2,438 views
この記事は最終更新から 372日 が経過しています。
1. 全テスト結果を取得する。
cuda-convnet のテスト結果出力機能を使うと、各テスト画像について出力層の全ユニットの出力値が取得できる。
例えば、学習結果 ConvNet__2014-07-09_22.31.05 が存在している場合、以下のように取得できる。
[user@linux]$ python shownet.py -f ./save/ConvNet__2014-07-09_22.31.05 --write-features=probs --feature-path=../tmp/
実行した結果、–feature-path で指定したディレクトリにテスト結果が出力される。
[user@linux]$ ll 合計 436 -rw-rw-r--. 1 user user 78 7月 9 22:54 2014 batches.meta -rw-rw-r--. 1 user user 440191 7月 9 22:54 2014 data_batch_6
まずは出力された batches.meta の中身を見てみる。
>>> import cPickle as cp
>>> mt = cp.load(open('batches.meta'))
>>> mt.keys()
['num_vis', 'source_model']
>>> mt['num_vis']
10
num_vis からラベル数が取得できるようだ。
次に data_batch_6 の中身を見てみる。
>>> sv = cp.load(open('data_batch_6'))
>>> sv.keys()
['labels', 'data']
>>> sv['labels']
array([[ 3., 8., 8., ..., 5., 1., 7.]], dtype=float32)
>>> sv['data']
array([[ 2.12459755e-03, 2.84853554e-03, 8.47100373e-03, ...,
1.67425780e-03, 6.06818078e-03, 1.81574584e-03],
[ 9.24929883e-03, 9.61963892e-01, 7.97947752e-04, ...,
7.32670560e-06, 2.74835732e-02, 3.86457832e-04],
...,
[ 6.13748282e-02, 3.04950565e-01, 1.83501482e-01, ...,
1.76601484e-02, 1.54394070e-02, 5.21140127e-03],
[ 7.03860400e-03, 1.66299902e-02, 1.75639763e-02, ...,
6.83449626e-01, 1.96132925e-03, 3.77259240e-03]], dtype=float32)
labels には正解ラベル、data には各画像の出力層全ユニット出力値が書かれている。
2. error matrixを作成する。
上記(1)で作成したデータから error matrix を作成する関数は以下の通り。
拙いPythonスキルで試行錯誤しながら書いたので無駄がいっぱいあるかも…
import cPickle as cp
import numpy as np
def makeErrorMatrix( metaFile, dataFile ):
mt = cp.load(open(metaFile))
sv = cp.load(open(dataFile))
nLabel = mt['num_vis']
nImage = sv['labels'].shape[1]
print '# of label : %d' % nLabel
print '# of image : %d' % nImage
maxAryRaw = np.uint8(np.argmax(sv['data'], 1))
maxArySpv = np.uint8(sv['labels'].T.flatten())
errorMatrix = np.zeros((nLabel,nLabel),dtype=int)
for i in range(0,nImage):
x = maxAryRaw[i]
y = maxArySpv[i]
errorMatrix[y][x] = errorMatrix[y][x] + 1
np.savetxt('errmtx.csv', errorMatrix, fmt='%d', delimiter=',')
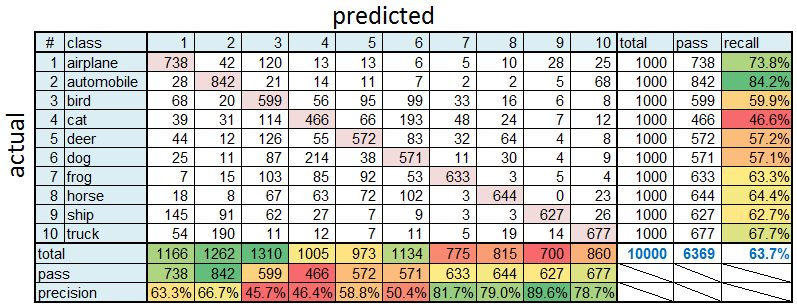
CIFAR-10 のテスト結果から作成したCSVファイルはこれ(↓)
738, 42,120, 13, 13, 6, 5, 10, 28, 25 28,842, 21, 14, 11, 7, 2, 2, 5, 68 68, 20,599, 56, 95, 99, 33, 16, 6, 8 39, 31,114,466, 66,193, 48, 24, 7, 12 44, 12,126, 55,572, 83, 32, 64, 4, 8 25, 11, 87,214, 38,571, 11, 30, 4, 9 7, 15,103, 85, 92, 53,633, 3, 5, 4 18, 8, 67, 63, 72,102, 3,644, 0, 23 145, 91, 62, 27, 7, 9, 3, 3,627, 26 54,190, 11, 12, 7, 11, 5, 19, 14,677
MS-Excelで整形すると、それっぽい error matrix が出来上がる。
今回の分類結果を見ると…
1) recallを見るとautomobileの正解率が突出して高いように見えるが、precisionを見ると正確さは平均並み。
→ 全テストデータ中でautomobileと認識される数は多いが、実際にautomobileである確率は並
2) recallを見るとshipの正解率は平均並みだが、precisionを見ると正確さは突出している。
→ shipと認識されたときに、本当にshipである確率が高い。
3) truckをautomobileとよく間違える。
→ 写真だけ見たら確かに似てるか…
4) catとdogはお互いによく間違える。
→ これもシルエットだけ見たら区別がつかないかも…
などの特徴が見られて面白い。