4,014 views
この記事は最終更新から 418日 が経過しています。
1. 試してみたいこと
(6) 自分の手書き文字を認識させてみる では、自作の octave版シンプル構成ニューラルネットに自筆の数字画像を自動認識させてみた。下記のように、どれも意地悪でない素直な数字画像を描いたつもりだが、MNISTテスト画像で 90% 以上の正解率を出したニューラルネット上での自筆画像の正解率は 65% (13/20) であった…
 OK |
 OK |
 OK |
 OK |
 OK |
 OK |
 OK |
 OK |
 NOK |
 OK |
 OK |
 OK |
 NOK |
 NOK |
 NOK |
 OK |
 OK |
 NOK |
 NOK |
 NOK |
チープな自作ニューラルネットに対して (15) cuda-convnetでMNIST自動認識(その2) では、cuda-convnet の強力パワーを利用してリッチなネットワーク構成で学習した結果、正解率 98% のニューラルネットが出来上がった。今回は、上記の残念な結果になってしまった自筆画像を、このニューラルネットに自動認識させてみたい。
2. 入力データを作らなければ
自筆の数字画像はただのPNG画像ファイルのため、これを cuda-convnet に入力できる形式に変換しなければならない。実現方法は単純だ。
| (1) | PNG形式の自筆数字画像ファイルを、MNIST生データ形式(=MNISTサイトからダウンロードしてきたときのファイル形式)に変換する。 |
| (2) | 作成したMNIST生データ形式ファイルを (13) cuda-convnet用MNISTデータを作る(その3) で作成した data_batch_n 作成プログラムで cuda-convnet 入力ファイル形式に変換する。 |
| (3) | cuda-convnetを test-onlyで実行させる。 |
入力データは以下のプログラムで作成した。
拙いPythonスキルで試行錯誤しながら書いたので無駄がいっぱいあるかも…
import numpy as np
import Image
import struct
import glob
data = ''
labl = ''
data += struct.pack('>4i', 0, 20, 28, 28) # dummy header
labl += struct.pack('>2i', 0, 20)
files = glob.glob('./*.png')
files.sort()
for file in files:
#------------------------
# (1)make label data
#------------------------
lbl = file.split('_')
lbl = int(lbl[1])
labl += struct.pack('B', lbl)
#------------------------
# (2)make image data
#------------------------
img = Image.open(file)
d = np.array(img)
d = np.delete(d, 3, 2) # index=3, axis=2 : RGBA -> RGB
d = np.mean(d, 2) # RGB -> L
d = np.swapaxes(d, 0, 1)
d = np.uint8(d.T.flatten('C')) # [y][x] -> [y*x]
ld = d.tolist() # numpy object -> python list object
ad = struct.pack('784B', *ld)
data += ad
fp = open('my_MNIST_label','w')
fp.write(labl)
fp.close()
fp = open('my_MNIST_data','w')
fp.write(data)
fp.close()
# make data_batch_n
import makeDataBatch
makeDataBatch.make_data_batch_all('','','my_MNIST_data','my_MNIST_label',10000)
3. cuda-convnetで自動認識実行(学習10epoch)
きれいにならべて結果表示できるように shownet.py に少々手を加えた後に実行してみた。
[user@linux]$ SAVEDATA=../save/MNIST/ConvNet__2014-07-09_22.10.42/ [user@linux]$ python shownet.py -f $SAVEDATA --show-preds=probs --test-range=8
結果は…

15/20で正解率 75%
数字の 4 と 6 が全滅…
各数字10,000枚も学習していて、テストでは 98% も正解しているのに…
自分が描いた4と6はそんなに世の中の普通からずれているのか?
4. ちょっと気になるので
「本当に自分の 4 と 6 は汚いのか?」
「もともと 4 と 6 は自動認識が難しいのではないか?」
と自分を納得させたく、(16) cuda-convnetの結果からerror matrixを作成 の手順で、正解率 98% のテスト結果の error matrix を作成し、眺めてみたくなった。
結果は…
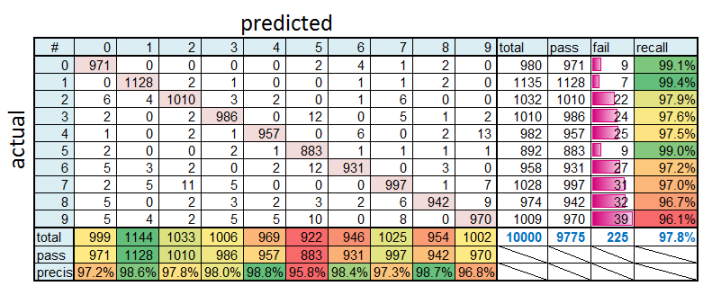
4 は 9 と間違えることが多いようだ。
6 は 5 と間違えることが多いようだ。
確かに自分の描いた 6 も 5 と誤認識されているが、931/958 に入れず 12/958 に入ってしまうレアな形の字を 2/2の確率で描けたことがすごいのでは…
それでも…
error matrixを眺めてみると、特別 4 と 6 に弱いわけではなさそうだ。
ということは、自分の字が汚いということか…
ん?98.0%が 97.8%になっているのはなぜ?
5. cuda-convnetで自動認識実行(学習10,000epoch)
さらにEPOCH数を10,000回に設定し、12時間かけて学習させてみたら以下のような結果になった。
MNISTトレーニングデータに関しては 99.9% の正解率、MNISTテストデータは 98.8% だ!
======================================================= (1.254 sec) 10000.1... logprob: 0.008284, 0.000900 (0.623 sec) 10000.2... logprob: 0.007593, 0.000700 (0.622 sec) 10000.3... logprob: 0.007735, 0.000600 (0.622 sec) 10000.4... logprob: 0.008328, 0.000500 (0.622 sec) 10000.5... logprob: 0.007779, 0.000100 (0.622 sec) 10000.6... logprob: 0.007282, 0.000200 ======================Test output====================== logprob: 0.034618, 0.011600
この学習結果を使用して自筆テストデータを自動認識させてみた結果は、正解数 18/20, 正解率 90% と向上した。

ちなみにこのときのMNISTテストデータの error matrix は以下の通り。

でも何か納得がいかない…