2,820 views
この記事は最終更新から 1584日 が経過しています。
(26) cuda-convnet2で二値分類器を作ってみる の続き…
(10) cuda-convnetのレポート表示 と同じ手順でレポート表示できる。
(1) loss curveを表示
SAVEDATA=ConvNet__2014-09-15_10.58.02 python shownet.py --load-file $SAVEDATA --show-cost=dce

(2) error curveを表示
SAVEDATA=ConvNet__2014-09-15_10.58.02 python shownet.py --load-file $SAVEDATA --show-cost=dce --cost-idx=1
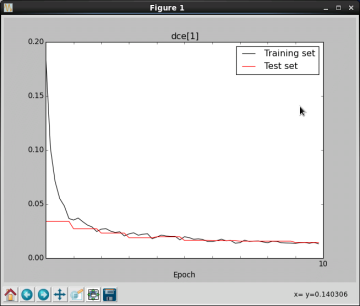
(3) accuracy curveを表示
SAVEDATA=ConvNet__2014-09-15_10.58.02 python shownet.py --load-file $SAVEDATA --show-cost=dce --cost-idx=2 # unit#1 precision python shownet.py --load-file $SAVEDATA --show-cost=dce --cost-idx=3 # unit#1 recall python shownet.py --load-file $SAVEDATA --show-cost=dce --cost-idx=4 # unit#2 precision python shownet.py --load-file $SAVEDATA --show-cost=dce --cost-idx=5 # unit#2 recall python shownet.py --load-file $SAVEDATA --show-cost=dce --cost-idx=6 # unit#3 precision python shownet.py --load-file $SAVEDATA --show-cost=dce --cost-idx=7 # unit#3 recall

(4) 全テストデータの出力層出力値を取得
手順1: 学習を実行する。
(26) cuda-convnet2で二値分類器を作ってみる を参照のこと。
手順2: 学習済みデータを指定して test-only で cuda-convnet2を実行する。
BASEPATH=/home/user/cuda/cuda-convnet2 SAVEDATA=$BASEPATH/save/ConvNet__2014-09-15_10.58.02 FEATPATH=$BASEPATH/tmp TRGLAYER=fcOut TEST_RANGE=7 python convnet.py --load-file ${SAVEDATA} \ --test-only 1 \ --test-range $TEST_RANGE \ --write-features $TRGLAYER \ --feature-path $FEATPATH
手順3: 出力されたデータファイルの中身を見る。
$ls batches.meta data_batch_7
pythonでシリアライズしたデータなので、pythonでデシリアイズして中身を見る。
$ python
[‘labels’] には正解値が、[‘data’] には出力値が格納されている。
どちらも 10,000データ x 3ユニット = 30,000個のデータを持つ。
>>> import numpy as np
>>> import cPickle as cp
>>>
>>> da = cp.load(open('data_batch_7'))
>>> da.keys()
['labels', 'data']
>>> data_raw = da['data'] # raw output
>>> data_lbl = da['labels'] # true label
>>> data_raw = np.asarray(data_raw)
>>> data_lbl = np.asarray(data_lbl)
>>> data_raw.shape
(10000, 3)
>>> data_lbl.shape
(3, 10000)
>>> data_lbl = data_lbl.T
>>> data_lbl.shape
(10000, 3)
取得した正解値 data_lbl と出力値 data_raw の先頭10個だけを参照してみる。
>>> data_lbl[0:10,:] array([[ 1., 0., 0.], [ 0., 1., 0.], [ 1., 0., 0.], [ 0., 1., 1.], [ 0., 1., 0.], [ 1., 0., 0.], [ 0., 1., 0.], [ 1., 0., 1.], [ 1., 0., 0.], [ 1., 0., 1.]], dtype=float32) >>> data_raw[0:10,:] array([[ 9.98521745e-01, 1.49850443e-03, 4.11541946e-03], [ 1.20352823e-02, 9.88052726e-01, 3.22542548e-01], [ 9.94093001e-01, 5.99678187e-03, 7.45591475e-03], [ 2.92361937e-02, 9.71927702e-01, 9.64868903e-01], [ 2.93485690e-02, 9.70762134e-01, 6.91684261e-02], [ 9.99665618e-01, 3.34766519e-04, 2.66197207e-03], [ 1.03651799e-01, 8.95208240e-01, 1.80083804e-03], [ 9.62865233e-01, 3.65868807e-02, 8.87887657e-01], [ 2.12325543e-01, 8.14015448e-01, 7.86685292e-03], [ 9.76591468e-01, 2.24058982e-02, 8.57828259e-01]], dtype=float32)
出力値を 閾値0.5で 2値化した結果を data_rth に取得し、これも先頭から10個だけを参照してみる。
そこそこ学習が進んでいるので上記の正解値 data_lbl とほぼ同じ値だ。(1個だけ間違いあり)
>>> data_rth = (data_raw >= 0.5)*1.0
>>> data_rth[0:10,:]
array([[ 1., 0., 0.],
[ 0., 1., 0.],
[ 1., 0., 0.],
[ 0., 1., 1.],
[ 0., 1., 0.],
[ 1., 0., 0.],
[ 0., 1., 0.],
[ 1., 0., 1.],
[ 0., 1., 0.],
[ 1., 0., 1.]])
ここから一気にトータルのエラー率を算出してみる。
出力ユニットNo.1,2,3の順に不正解数は 289, 293, 537個、
出力値の総数は 3ユニット x 10,000データで 30,000個だ。
>>> out1_raw = data_raw[:,0] >>> out2_raw = data_raw[:,1] >>> out3_raw = data_raw[:,2] >>> >>> out1_lbl = data_lbl[:,0] >>> out2_lbl = data_lbl[:,1] >>> out3_lbl = data_lbl[:,2] >>> >>> out1_rth = (out1_raw >= 0.5) * 1 >>> out2_rth = (out2_raw >= 0.5) * 1 >>> out3_rth = (out3_raw >= 0.5) * 1 >>> >>> out1_lbl = (out1_lbl >= 0.5) * 1 >>> out2_lbl = (out2_lbl >= 0.5) * 1 >>> out3_lbl = (out3_lbl >= 0.5) * 1 >>> >>> out1_diff = np.where(out1_rth != out1_lbl) >>> out2_diff = np.where(out2_rth != out2_lbl) >>> out3_diff = np.where(out3_rth != out3_lbl) >>> >>> diff1 = len(out1_diff[0]) >>> diff2 = len(out2_diff[0]) >>> diff3 = len(out3_diff[0]) >>> diff1 289 >>> diff2 293 >>> diff3 537 >>> >>> errorRate = float((diff1 + diff2 + diff3)) / (len(out1_lbl) + len(out2_lbl) + len(out3_lbl)) >>> errorRate 0.0373
ここまでの作業で 「生出力値から計算したエラー率」=「学習時に表示されたエラー率」 であることが確認できた。
======================Test output======================
dce: (crossent) 0.319596, (err) 0.037300, (Godd) 0.965015, 0.978518, (Geven) 0.977137, 0.963053, (Gtri) 0.925373, 0.940106
アクセス数(直近7日): ※試験運用中、BOT除外簡易実装済2026-06-19: 0回 2026-06-18: 0回 2026-06-17: 2回 2026-06-16: 0回 2026-06-15: 0回 2026-06-14: 1回 2026-06-13: 0回