
1,350 views
【1】やりたいこと
PyTorchの使い方が少しずつわかってきたので、画像分類とは違うテーマにも挑戦してみたい。
次に選んだテーマは…
強化学習でゲームAI作り!
学習しながら楽しめる物が欲しいので、ゲームAIを作りたい。
本当はスーパーマリオを自動クリアできる AIなんてものを作りたいけど、なかなか難しそうだ。
まずは オセロAI から始めてみることにした。

【2】やってみる
1) 方針
基礎的な強化学習手法である Q学習 を使う。
つまり、
ある状態(=盤面上の石の配置)において、
どの行動(=指し手)を選択すれば、
良い最終結果(=高い報酬)が得られるか?
を Neural Networkに学習させるのだ。
簡単に言えば、
局面ごとに「どこに置けば最高のゴールにたどり着けるか」を表す
高精度の二次元マップをモデルに作らせる
と言える。
2) ロジック概要
(1) Q学習のアルゴリズム
| 状態(State) | 𝑠 |
| 行動(Action) | 𝑎 |
| 報酬(Reward) | 𝑟 |
| 次の状態 | 𝑠′ |
| 学習率(Learning rate) | 𝛼 |
| 割引率(Discount factor) | 𝛾 |
| Q値(状態行動価値関数、Q関数) | 𝑄(𝑠,𝑎) |
Q値の更新式
Q学習では、Qテーブルという行列で各状態と行動の組に対する価値(Q値)を管理する。
以下のベルマン方程式に基づいて更新する。
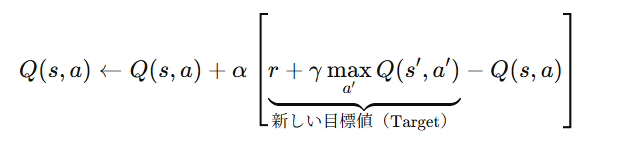

各項の意味
| 𝑄(𝑠,𝑎) | 現在のQ値(期待値) |
| 𝑟 | 実際に得られた報酬 (勝利:+1, 敗戦:-1, 石を返す:n x 0.1, 四隅を取る:n x 0.5 など) |
| max𝑎′ 𝑄(𝑠′,𝑎′) | 次の状態で最善の行動を選択時に得られるQ値(将来の最大報酬の見込み) |
| 𝛾 | 割引率、将来の報酬に対する重み付け(0に近いと短期、1に近いと長期志向) |
| 𝛼 | 新しい経験をどれだけ反映させるか(学習率) |
まだ分かりにくいので、さらに平たくかみ砕いてみる。
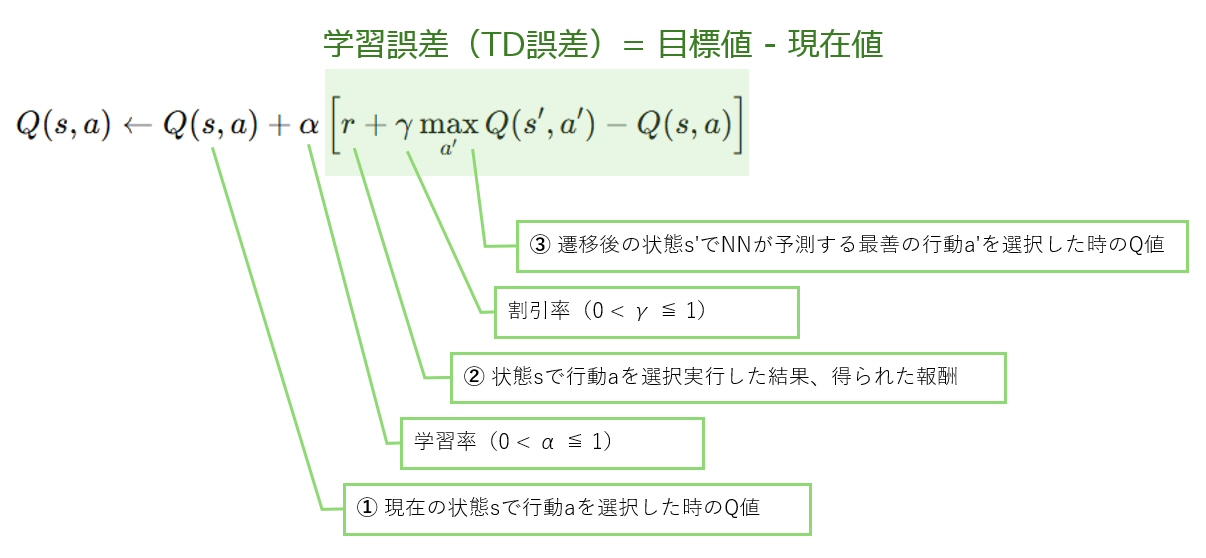

| ① | 現在の盤面(s)で、そこに石を置いた(a) → NNでQ値(報酬総額)を予測 | |
| ② | 現在の盤面(s)で、そこに石を置いた(a)結果、得られた報酬(r) | 勝利:+1, 敗戦:-1, 角奪取:+0.5 等々 |
| ③ | 行動の結果、次の盤面(s’)に移り、最善の場所に石を置いた(a’)としたら? → NNでQ値を予測。これを教師データ(=理想とするQ値)として誤差算出し、逆伝播でNNを更新する。 |
ただし…
本来相手の手番であるはずの s’ を学習で使ってよいのかは疑問だ。
Q学習の目的は「未来の最終報酬(Win:+1, Lose:-1, Draw:0)を、今の行動の価値に反映すること」。
であるならば、
自分 → 相手 → 自分 → … → 勝利(+1)
という流れの中で、「相手の手番が途中に挟まっているのに、自分視点のQ値を連続的に更新していてよいのか?
対戦型ゲームAIにおけるQ学習の手法について、先人の知恵をお借りしたいなぁ…
→ 要調査
(2) 強化学習の手順
Step1:
・モデル同士を対戦させる。
→ 勝利、敗戦、引分けすべての 指し手の履歴(=後の学習データ) を記憶しておく。
・対戦する両モデルともに最初は「ランダムに石を置くことしかできない」という幼児のような状態で開始する。(参考: AlphaZero)
Step2:
・Step1で収集した指し手の履歴データを使い、モデルを学習させる。
・このとき、一度に数十手をミニバッチ学習させる。(GPUの出番)
・入力は 6×6の盤面上の石の配置
・出力は 6×6の盤面上の期待報酬 Q値 (=「そのマスに石を置いたら〇点」が個々のマスに書かれたQ値マップ)
・指し手履歴データの「次の一手」を正解として誤差算出し、Neural Networkに学習させる。
・このとき、ひっくり返した石の枚数に応じて追加報酬を正解値に加算する。
・同様に、四隅を取ったら大きめの追加報酬を正解値に加算する。
・1試合が終了時、勝てば大きめのプラス報酬を加算、負ければ大きめのマイナス報酬を加算する。
Step3:
・上記Step1, Step2をひたすら繰り返す。
→ 自己対戦型強化学習(Self-Play Reinforcement Learning)により徐々に強くなる。
(3) 対戦相手候補モデルを徐々に増やす
・学習中に、対戦相手候補モデルリストを自動で整備する。
・最初にリストに入れるのは、ランダムに石を置くだけのモデル一つだけ。
・強くなって一定の勝率を超えるモデルに成長したら、その時の自分自身をリストに追加する。
・対戦候補リストの中からランダムに対戦相手モデルを選択する。
→ 過学習を回避する。 「斎藤さんにだけなら勝てる!」ではダメ
→ 局所最小値へのはまり込みを回避する。 成長の壁・行き詰まり・停滞を乗り越える。
3) 実装方法
(1) 使用するライブラリ
・PyTorchを使う。
(2) 入力層
・6×6のマス目上の 自分/相手の石の配置 を表す。
| 1 | 自分の石 |
| -1 | 相手の石 |
| 0 | 石無し |
例: ゲーム開始時の初回の入力値はいつもこれ(=自分/相手の石の配置)
| 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | -1 | 0 | 0 |
| 0 | 0 | -1 | 1 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 |
(2) 隠れ層
・いろいろ試してみたい。
・初版の CNN(浅めの4層)では、以下のように繋いだ。
[INPUT: 6×6]
→ [ CONV:[64][6][6] ] → ReLU
→ [ CONV:[128][6][6] ] → ReLU
→ [ CONV:[128][6][6] ] → ReLU
→ [ FC:[128] ] → ReLU
→ [ OUTPUT:[36(6×6)] ]
(3) 出力層
・6×6のマス目上に期待報酬 Q値マップ を出力するように学習する。
・実際には 6×6=36個のフル接続層にする。
・出力値は正負の実数値(正規化しない生の出力値)
偽の値よりも良いので、後でプログラム実行時にダンプした本物を貼付けよう
その他、後日追記
4) プログラムソースコード
量が多いので、後日一つずつ掲載したい。
ソースファイルごとにコメントをきれいに書き直す必要もある…
5) 直近 2日間で作り出したモデルたち
以下の 3種類のネットワーク構成で学習済みモデルを作った。
| (1) | CNN(4層) |
| (2) | CNN(8層) |
| (3) | CNN(7層:スキップ結合あり) |
(1)については学習所要時間が短いため、超パラメータセット x 50組ぐらい実行してみた。
(2),(3)は層が深くて実行時間がかかるので数回しか試していない。
直近 1.5日で試した中で良好な結果が得られた上位 24モデルは下表のとおり。
※まだ作って2日目なので、今後ぐんぐん抜かれる予定(であってほしい)
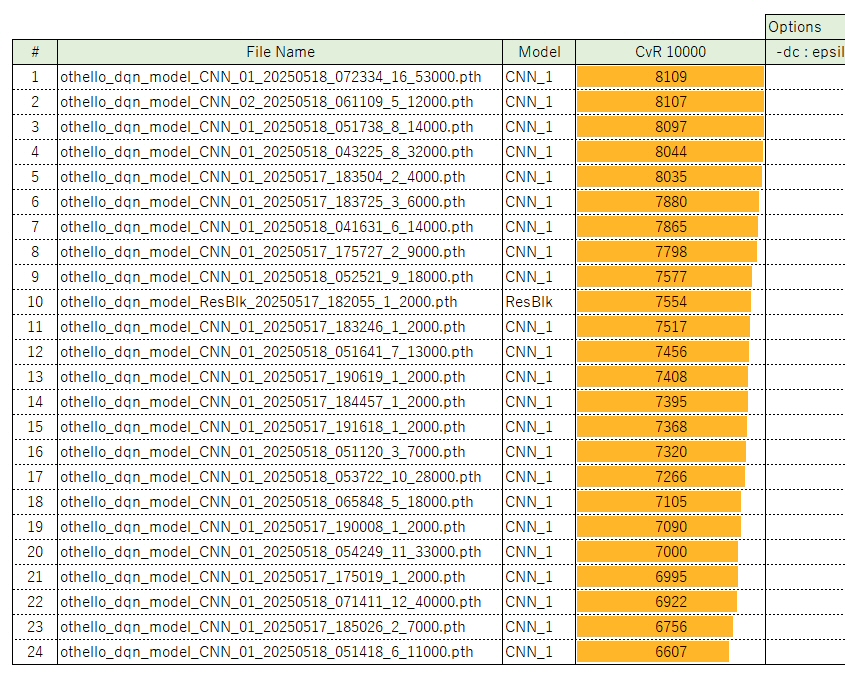

ちなみに CvR 10000 は勝手に作った指標で
COM vs Random 10000回対戦時の勝利数 を表す。(%表記よりも嬉しいので)
個人的にはこれを Level と呼んでいる。
→ Lv.8000 は、Random指し手のコンピュータを相手に 10000戦して 8000勝の実績 ということだ。
【3】所感
直近二日間で最強のはず の Lv.8109(vs ランダム指し手 8109勝/10000戦)のオセロAIだが…
大して IQの高くない自分と対戦してこの結果だ。
こちら(↑)は JavaScript + CGI(Python) で学習済みモデルを動かして対戦できる Webアプリを作ってみた。
Web公開したいが、このブログを設置している共用サーバでは PyTorchが coreったようなので要調査。
現状は自宅鯖でのみ実行できている。
平均的な人間代表として対戦した感想は…
まだまだダメだな・・・
四隅が空いているのに取らなかったり、
人間側に大逆転の一手があるのに防がなかったり、
まだまだ報酬設定が甘い のだろう。
また、学習停滞時にその 沼から脱する方法 も要勉強だ。
戦術の異なる複数種類の過去モデルたちと対戦させて頭の使い方を変えさせたり、
負けが続いたら戦術ゼロのランダムロジックを相手に自尊心を挽回させたり、
探索選択率 ε の値を動的に調整してみたり、
色々と試そうとすると高速実行できる環境が欲しい。
我が家には 36コア72スレッドの Dual CPU搭載の Z840があるが、シングルスレッドパワーが超非力で、機械学習に使うと遅いくらいに感じる。
また、24コア 32スレッド且つ Single threadも強い Core i9 13900はパワフルで良いが、 メインパソコンなので機械学習専用機として専念させられない。
先々月に GeForce RTX 5070ti を購入したが、こちらは Adobeツールを使った仕事用にメインパソコンに搭載しているので、これも機械学習専用にはできない。
少しお金がかかってしまうが、機械学習専用機を 1台作るかなぁ・・・
【4】今後の計画
次回以降の投稿では、今回実装した初版のロジックを自分用に解説したい。
そして、気付いた点を記録しておき、後の改良作業につなげたい。
最終的には・・・
CvR 9500 の自分史上最強モデルを作りたい!
というのが夢です。
楽しい遊びを見つけてしまったかもしれない・・・