9,893 views
この記事は最終更新から 418日 が経過しています。
1. sigmoidの代わりにtanh
活性化関数は sigmoid の他に tanh も使用するらしい。
分類タスクで使う活性化関数は、入力値に対して出力値が一定範囲内に制限されるならば、どんな関数でもよいらしい。
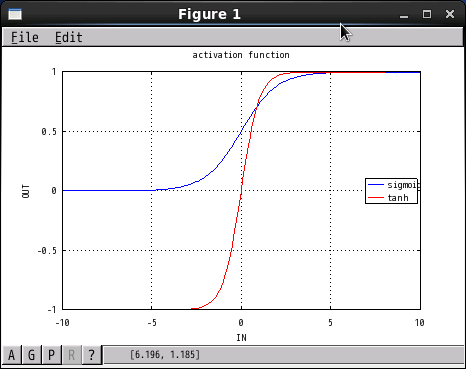
両関数の入力に対する出力をグラフにしてみた。
sigmoidと比較すると tanhは縦に長く、横に短く、0対象になっている。
x=0付近の変化に敏感に反応する。
octave:1> x = [-10:0.1:10];
octave:2> y_sigmoid = 1./(1+exp(-x));
octave:3> y_tanh = tanh(x);
octave:4> figure;
octave:5> plot(x,y_sigmoid,'b');
octave:6> hold on;
octave:7> plot(x,y_tanh,'r');
octave:8>
octave:8> title('activation function');
octave:9> xlabel('IN');
octave:10> ylabel('OUT');
octave:11> h = legend ({'sigmoid', 'tanh'}, 'location', 'east');
octave:12> grid on;
2. 実験結果
シンプル構成初版では、全層の活性化関数をsigmoidとしていた。
今回は、隠れ層をtanh, 出力層をsigmoid にして MNIST自動認識を実行してみる。
(1) 3層 [784]-[16]-[10] 88.4%(-0.6%)
octave:1> NNET_control([784 16 10], 1) EPOCH No.1 [ 0] 929 / 980 ( 94.8%) [ 1] 1101 / 1135 ( 97.0%) [ 2] 904 / 1032 ( 87.6%) [ 3] 754 / 1010 ( 74.7%) [ 4] 880 / 982 ( 89.6%) [ 5] 773 / 892 ( 86.7%) [ 6] 881 / 958 ( 92.0%) [ 7] 926 / 1028 ( 90.1%) [ 8] 815 / 974 ( 83.7%) [ 9] 873 / 1009 ( 86.5%) Total 8836 / 10000 ( 88.4%)
(2) 3層 [784]-[24]-[10] 88.8%(-1.1%)
octave:2> NNET_control([784 24 10], 1) EPOCH No.1 [ 0] 951 / 980 ( 97.0%) [ 1] 1113 / 1135 ( 98.1%) [ 2] 873 / 1032 ( 84.6%) [ 3] 870 / 1010 ( 86.1%) [ 4] 839 / 982 ( 85.4%) [ 5] 769 / 892 ( 86.2%) [ 6] 877 / 958 ( 91.5%) [ 7] 911 / 1028 ( 88.6%) [ 8] 835 / 974 ( 85.7%) [ 9] 847 / 1009 ( 83.9%) Total 8885 / 10000 ( 88.8%)
(3) 3層 [784]-[32]-[10] 81.8%(-8.8%)
octave:4> NNET_control([784 48 10], 1) EPOCH No.1 [ 0] 949 / 980 ( 96.8%) [ 1] 1118 / 1135 ( 98.5%) [ 2] 924 / 1032 ( 89.5%) [ 3] 5 / 1010 ( 0.5%) ←??? [ 4] 908 / 982 ( 92.5%) [ 5] 781 / 892 ( 87.6%) [ 6] 882 / 958 ( 92.1%) [ 7] 906 / 1028 ( 88.1%) [ 8] 822 / 974 ( 84.4%) [ 9] 884 / 1009 ( 87.6%) Total 8179 / 10000 ( 81.8%)
(4) 3層 [784]-[64]-[10] 89.6%(-1.2%)
octave:5> NNET_control([784 64 10], 1) EPOCH No.1 [ 0] 945 / 980 ( 96.4%) [ 1] 1114 / 1135 ( 98.1%) [ 2] 900 / 1032 ( 87.2%) [ 3] 915 / 1010 ( 90.6%) [ 4] 883 / 982 ( 89.9%) [ 5] 735 / 892 ( 82.4%) [ 6] 902 / 958 ( 94.2%) [ 7] 903 / 1028 ( 87.8%) [ 8] 814 / 974 ( 83.6%) [ 9] 851 / 1009 ( 84.3%) Total 8962 / 10000 ( 89.6%)
(5) 3層 [784]-[128]-[10] 83.9%(-7.6%)
octave:6> NNET_control([784 128 10], 1) EPOCH No.1 [ 0] 964 / 980 ( 98.4%) [ 1] 1115 / 1135 ( 98.2%) [ 2] 944 / 1032 ( 91.5%) [ 3] 915 / 1010 ( 90.6%) [ 4] 903 / 982 ( 92.0%) [ 5] 809 / 892 ( 90.7%) [ 6] 886 / 958 ( 92.5%) [ 7] 938 / 1028 ( 91.2%) [ 8] 24 / 974 ( 2.5%) ←??? [ 9] 891 / 1009 ( 88.3%) Total 8389 / 10000 ( 83.9%)
(6) 4層 [784]-[256]-[64]-[10] 72.3%(-19.6%)
octave:7> NNET_control([784 256 64 10], 1) EPOCH No.1 [ 0] 1 / 980 ( 0.1%) ←??? [ 1] 1113 / 1135 ( 98.1%) [ 2] 905 / 1032 ( 87.7%) [ 3] 0 / 1010 ( 0.0%) ←??? [ 4] 842 / 982 ( 85.7%) [ 5] 789 / 892 ( 88.5%) [ 6] 885 / 958 ( 92.4%) [ 7] 932 / 1028 ( 90.7%) [ 8] 888 / 974 ( 91.2%) [ 9] 875 / 1009 ( 86.7%) Total 7230 / 10000 ( 72.3%)
すべてのレイヤー構成で全sigmoid版のスコアを下回った…
tanhの使い方が間違っているのか?
3. プログラムのソースコード
前版からの変更は以下の7ファイルのみ。
(1) NNET_control.m
function NNET_control( num_unit_of_each_layer, num_EPOCH ) % 学習画像・ラベル、テスト画像・ラベルをファイルから読み込み [train_img, train_lbl] = load_MNIST( '../data/train-images-idx3-ubyte', '../data/train-labels-idx1-ubyte' ); [test_img, test_lbl ] = load_MNIST( '../data/t10k-images-idx3-ubyte', '../data/t10k-labels-idx1-ubyte' ); % 各画像データを 0.0~1.0の範囲に正規化 train_img = train_img / 255; test_img = test_img / 255; % 指定された層数、ユニット数でニューラルネットワークを作成 nn = NNET_setup( num_unit_of_each_layer ); % 指定EPOCH回数だけ繰り返す for epoch=1 : num_EPOCH % 学習実行 nn = NNET_learn( nn, train_img, train_lbl ); % テスト実行 result = NNET_test( nn, test_img, test_lbl ); % テスト結果を表示 printf('\nEPOCH No.%d\n', epoch); for i=1: 10 printf('[%2d] %4d / %4d (%5.1f%%) \n', i-1, result(i,2), result(i,1), result(i,2)/result(i,1)*100); end sum_result = sum(result,1); printf('Total %5d / %5d (%5.1f%%) \n', sum_result(2), sum_result(1), sum_result(2)/sum_result(1)*100); fflush(1); end end
(2) NNET_setup.m
function nn = NNET_setup( num_unit_of_each_layer ) % 乱数生成器を初期化 rand('seed', 0); % 指定された層数を取得 num_layer = numel( num_unit_of_each_layer ); % 全層を初期化 for i=2 : num_layer % 現層と前層のユニット数を取得 num_unit_pre = num_unit_of_each_layer( i - 1 ); num_unit = num_unit_of_each_layer( i ); % 各結合線の荷重を -1~1の一様分布乱数で初期化 nn.layer{i}.weight = -1 + rand( num_unit, num_unit_pre ) * 2; % バイアスを初期化 nn.layer{i}.bias = zeros( num_unit, 1 ); % 活性化関数を登録 if i==num_layer % 出力層であればsigmoid nn.layer{i}.actfunc = @act_sigmoid; nn.layer{i}.dactfunc = @act_sigmoid_d; else % 隠れ層であればtanh nn.layer{i}.actfunc = @act_tanh; nn.layer{i}.dactfunc = @act_tanh_d; end end end
(3) NNET_propagation_forward.m
function nn = NNET_propagation_forward( nn, train_img ) % 入力層の出力値を記憶 nn.layer{1}.out = train_img(:); % [n0][1] % 全層について順伝播を実行 for i=2 : numel(nn.layer) % a = Σwz + bias w[n1][n0] z[n0][1] bias[n1][1] nn.layer{i}.actprm = nn.layer{i}.weight * nn.layer{i-1}.out + nn.layer{i}.bias; % out = sigmoid(a) out[n1][1] nn.layer{i}.out = nn.layer{i}.actfunc( nn.layer{i}.actprm ); end end
(4) NNET_propagation_back.m
function nn = NNET_propagation_back( nn, train_lbl ) % 層数を取得 num_layer = numel(nn.layer); % 出力層で検出された誤差量と逆伝播する勾配の初期値を算出 [err, nn.layer{num_layer}.grad] = lossfunc(nn.layer{num_layer}.out, train_lbl); % 全層について誤差逆伝播を実行 for i=num_layer : -1 : 2 % 直前層の各ニューロンに伝播する勾配を算出 % δout % ----- = w x h'(a) % δin % | δout| % grad = Σ|gout x -----| % | δin | % 配列要素数の同じ2パラメータを先に計算 grad[n1][1] out[n1][1] derr = nn.layer{i}.grad .* nn.layer{i}.dactfunc(nn.layer{i}.out); % Σ(w・derr) w[n1][n0] derr[n1][1] grad[n0][1] nn.layer{i-1}.grad = nn.layer{i}.weight' * derr; % 結合荷重の修正量を算出 % δE % ---- = grad・h'(a)・out % δw % IN側ユニット-OUT側ユニットの組み合わせごとに算出 out[n0][1] derr[n1][1] dw[n1][n0] nn.layer{i}.dweight = derr * nn.layer{i-1}.out'; % バイアスの修正量を算出 nn.layer{i}.dbias = derr; end end
(5) act_sigmoid.m
function y = act_sigmoid( x ) y = 1 ./ (1 + exp(-x)); % sigmoid end
(6) act_tanh.m
function y = act_tanh( x ) y = tanh(x); end
(7) act_tanh_d.m
function y = act_tanh_d( x ) y = 1 - x.^2; % tanh end
シンプル構成初版のプログラムソースコードはこちら。
(4) シンプル構成の初版は正解率91%
アクセス数(直近7日): ※試験運用中、BOT除外簡易実装済2026-08-03: 0回 2026-08-02: 0回 2026-08-01: 0回 2026-07-31: 1回 2026-07-30: 5回 2026-07-29: 0回 2026-07-28: 2回
今更ですが…
2*sigmoid(x) – 1 = tanh(0.5*x)
なので,活性化関数が原因というよりは
初期化や入力の正規化に問題があるのでしょう
ありがとうございます。m(_ _)m
最近は Tensorflowを使い始めましたので、そちらで実験してみます。