759 views
この記事は最終更新から 368日 が経過しています。
【1】やりたいこと
PyTorchや TensorFlowなどの機械学習ライブラリを使わない場合、ライブラリが提供してくれている機能を自力実装する必要がある。
前回、前々回の投稿では、活性化関数 tanh(x) と sigmoid(x) の微分を見た。
「逆伝播で使う微分」シリーズの投稿は以下の通り。
(56) 逆伝播で使う tanh(x)の微分
(57) 逆伝播で使う sigmoid(x)の微分
(58) 逆伝播で使う ReLU(x)の微分 ←今回
(59) 逆伝播で使う MSE(平均二乗誤差)の微分
(60) 他クラス分類で使う Softmax
(61) 機械学習で多用されるネイピア数とは?
今回は、同じく活性化関数として使われる ReLUの微分について見てみる。
改めて見直すようなことは無いのだが備忘録・・・
【2】やってみる
1) ReLUとは?
ReLU(x), ReLU'(x) をまとめて図示する。
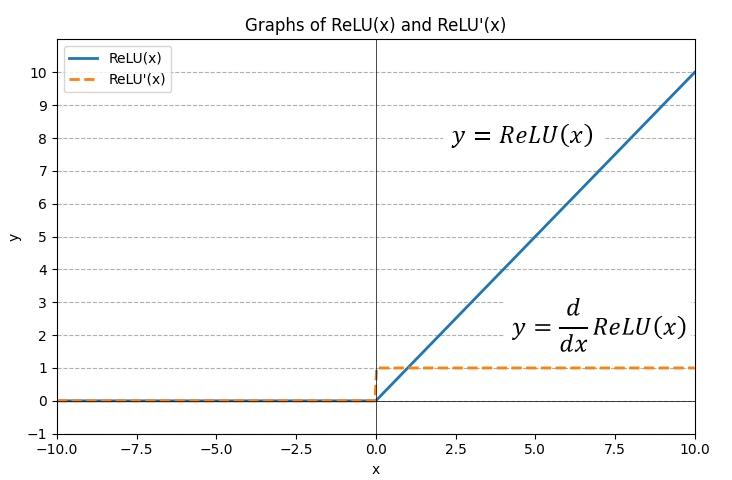
入力値 xの正負で出力値 yの算出式が変わる。
とってもシンプルな仕様で、計算時のマシン負荷が非常に低い。
| 入力値x | 出力値y | 微分値 |
|---|---|---|
| x > 0 | y = x | 1 |
| x ≦ 0 | y = 0 | 0 |
import numpy as np
import matplotlib.pyplot as plt
#///////////////////////////////////////////////////////////////////////////////
def relu(x): # ReLU関数
return np.maximum(0, x)
#///////////////////////////////////////////////////////////////////////////////
def relu_derivative(x): # ReLUの導関数
return np.where(x > 0, 1, 0)
#///////////////////////////////////////////////////////////////////////////////
x = np.linspace(-10, 10, 400) # x軸の値
y_relu = relu(x)
y_relu_prime = relu_derivative(x)
#///////////////////////////////////////////////////////////////////////////////
plt.figure(figsize=(10, 6)) # グラフの描画
plt.plot(x, y_relu, label="ReLU(x)", linewidth=2)
plt.plot(x, y_relu_prime, label="ReLU'(x)", linestyle='--', linewidth=2)
plt.title("Graphs of ReLU(x) and ReLU'(x)")
plt.xlabel("x")
plt.ylabel("y")
plt.xlim(-10, 10)
plt.ylim(-1, 11)
plt.yticks(np.arange(-1, 11, 1)) # Y軸を1刻みに設定
plt.grid(True, which='major', axis='y', linestyle='--') # Y軸グリッド
plt.axhline(0, color='black', linewidth=0.5)
plt.axvline(0, color='black', linewidth=0.5)
plt.legend()
plt.show()
2) S字関数ではなく ReLUが使われる理由は?
■長所
・勾配消失(vanishing gradient)を起こしにくい。
※S字型関数(例:sigmoid, tanh)は、入力の絶対値が大きくなると勾配(導関数の値)が 0 に近づく(飽和する)特性がある。
・計算が高速
・スパースな活性化を生む。
入力が負の場合に出力が 0 になるため、ニューロンの一部が自然に非活性(=0)となり、スパース性が得られる。
→ 過学習抑制やモデルの効率化に寄与。
・勾配が大きく残る・計算が軽い・スパース性等により、学習が早く安定しやすい。
スパース性:
「まばら」「少ない」「密度が低い」「ぎっしり詰まっていない、ところどころしか存在しない」
ニューラルネットワークで、出力が0になるニューロンが多い状態のこと。
参考:
・スパースな行列(sparse matrix): 要素のほとんどが 0 の行列
・スパース(sparse)なデータ: 多くの要素が「0」または「空」であるデータ
例:[0, 0, 0, 1, 0, 0, 2, 0] のように、値がある箇所が少ない
■短所
・Dead Neuron問題
入力が常に負の値ばかりになると、そのニューロンの出力が常に0になり、学習されなくなる(dead neuron)。
対策として Leaky ReLU, ELU, He初期化、適切な学習率(learning rate)の設定、Dropout等々を工夫する。
3) 個人的な ReLUとの出会い
初めて ReLUを知ったのは 2014年のこと。
当時、画像認識システム開発プロジェクトに従事していた時に、チームの頭脳だった賢い方からの指示で matlab実装したのが初めだったはず。
(その 3年後、我が子に名前をつけるときに、その方の名前の一文字をいただきました。)
活性化関数と言えば sigmoid or tanh と決めつけて使っていた自分には衝撃的だった。
えっ?
こんな単純なロジックでよいの?
入力値が大きくなったら爆発するでしょ?
入力値が負の時に勾配が消えるんですけど?
しかし・・・
その心配はすぐに期待へと変わった。
速い!
エラー値が下がる下がる! 学習が進む進む!
それ以来、Neural Networkを作るときには必ず組み込み、有効性を試している。
4) ReLU'(x)の計算式
定義:
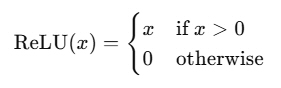
導関数:

マシン負荷が低い、このシンプルさが ReLUの特徴だ。
5) ReLUの微分を Pythonで実装する。
def relu(x):
return np.maximum(0, x)
def relu_derivative(x):
return np.where(x > 0, 1, 0)
シンプルな実装に見えるが、ここには Python + Numpyの底力が隠れている。
numpyのベクトル化関数を使っているので、入力値 xは多次元配列(ndarray)を使える。
→ ミニバッチデータ等、複数データをまとめて処理できる。
※実際のデータ並列処理はライブラリ内部に隠蔽されている。