745 views
この記事は最終更新から 386日 が経過しています。
【1】やりたいこと
DQNを使ったオセロAI作りを続けているが、ランダム指し手相手に勝率 90%で足踏み状態…
ルールが明確な問題に対しては、
第一次AIブーム(1960年前後)の探索・推論技術が強い
と聞いたので、気分転換にこれを作って動かしてみたい。
今回試すのは モンテカルロ法 だ。
モンテカルロ法とは、今から先の手を何通りもシミュレーション実行(=プレイアウト)し、
その結果の中から統計的に良さげな手を選ぶ手法のこと。
つまり…
自分の手番になったら、
そこから先の指し手を何通りもシミュレーションし、
その過程で打った指し手で木構造を作り、
最終的に数百回、数千回のシミュレーション結果の中から、
勝利に到達する可能性が一番高い一手を選ぶ
という戦術だ。
【2】やってみた
1) 設計
後日追記
2) 実装
後日追記
3) CvR 10000計測結果
Iterationsは、推論時のシミュレーション試行回数(=プレイアウト数 : # of playout)のこと。
Iterations=100であれば、一手を選ぶたびに、100通りのシミュレーションを行うということ。
シミュレーションでは指し手をランダムに選び、その結果が勝利であれば「そのルートは勝てる可能性あり」と重みづけをする。
(1) Iterations = 100
一手を打つたびに、100通りのシミュレーションを実行する。
試行した 100手の中から、勝利する可能性が高い最良の一手を選択する。
$ python main_CvR.py -p MCTS -n 10000 --mi 100 --mp 1 対戦数: 10000 AI 勝利数 : 9665 ランダム 勝利数: 45 引き分け : 290 AI(A) 勝率 : 99.54% [1] 4919.437496 sec : END Total elapsed time: 4919.437496 sec
(2) Iterations = 200
一手を打つたびに、200通りのシミュレーションを実行する。
試行した 200手の中から、勝利する可能性が高い最良の一手を選択する。
$ python main_CvR.py -p MCTS -n 10000 --mi 200 --mp 1 対戦数: 10000 AI 勝利数 : 9832 ランダム 勝利数: 12 引き分け : 156 AI(A) 勝率 : 99.88% [1] 9299.509499 sec : END Total elapsed time: 9299.509499 sec
(3) Iterations = 300
一手を打つたびに、300通りのシミュレーションを実行する。
試行した 300手の中から、勝利する可能性が高い最良の一手を選択する。
$ python main_CvR.py -p MCTS -n 10000 --mi 300 --mp 1 対戦数: 10000 AI 勝利数 : 9850 ランダム 勝利数: 6 引き分け : 144 AI(A) 勝率 : 99.94% [1] 13568.940375 sec : END Total elapsed time: 13568.940375 sec
(4) Iterations = 500
一手を打つたびに、500通りのシミュレーションを実行する。
試行した 500手の中から、勝利する可能性が高い最良の一手を選択する。
なんと CvR 9908 に到達した!
※CvR : 勝手に作った指標で、Random指し手を相手に 10000戦して何勝するかを表す値
9908勝 3敗 89引分 勝率 99.97%
$ python main_CvR.py -p MCTS -n 10000 --mi 500 --mp 1 対戦数: 10000 AI 勝利数 : 9908 ランダム 勝利数: 3 引き分け : 89 AI(A) 勝率 : 99.97% [1] 21839.737502 sec : END Total elapsed time: 21839.737502 sec
(5) Iterations = 1000~
Iteration=500の時点で、処理時間は 21839秒(≒6時間)も要した。
家庭用パソコンを 6時間超も高負荷状態にしていると、電源、マザボ、グラボ、CPU, SSD, その他諸々のパーツが傷み始めそうで怖い…
現時点で CvR 9908まで到達した。
頑張ってこれを 9950, 9960 にするためにパソコンを傷める必要は無いと判断する。
よって、Iterations ≧ 1000 は今は計測しないことにする。
4) 他モデルとの対戦結果
CvR 10000の計測結果から予想はしていたが・・・
ダントツでチャンピオンの座を奪取した!
対戦時間を短くしたかったので、Iterations=100(プレイアウト数=100回)で参戦した。
全185モデルの総当たり2回戦(先手、後手)での対戦成績は、321勝 20敗 27引分 勝率 94.1%

【3】人間(私)と対戦
過去二回、作成済みモデル総当たり戦のチャンピオンと対戦したが、こんな結果だった・・・
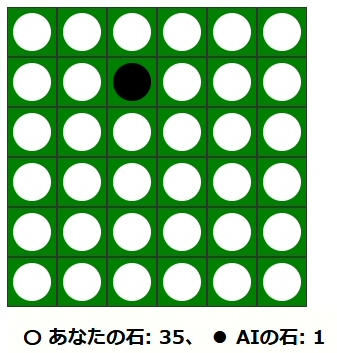

もしかして俺ってオセロ強いのか?
と勘違いしてしまうような結果だった。
今回はこれが勘違いであった現実が突き付けられた・・・
vs Iterations=5000

vs Iterations=1000

恥を覚悟で正直に書くと
Iterations > 500 の相手にはほとんど勝てない・・・
強い、強すぎる、化け物だ、モンテカルロ・・・
1960年代の技術だなんて軽視して申し訳ございませんでした。。。
【4】今後の方針
今回作ったモンテカルロ探索モデル(MCTS)は、あくまでも息抜きで作成したもの。
目標は Deep Q Networkを使った強化学習で CvR 9500超えのオセロAIを作ること!
なので、今回作った モンテカルロ探索AIは強化学習の良き対戦相手 になってもらおう。
モンテカルロ探索は、順伝播一発で結果が出るニューラルネットと比較して、推論に多くの時間を要する。
推論時のシミュレーション回数(=プレイアウト数)に依存して処理時間が大きく増える。
よって、より強い MCTSエージェントを相手にしようと思えば、処理の高速化が必須になる。
このため、シミュレーション実行をマルチスレッド、マルチプロセスによる並列実行で高速化 する必要がある。ただし Pythonにはマルチスレッド並列実行が出来ない GIL問題がある・・・
強化学習の相手になるということは、数千試合、数万試合の相手をすることになるので、1試合で 1秒縮まるだけでも数時間の差が出るのだ。
【5】所感
2010年以降に進歩した Deep learning 技術で作った AIが、
1960年代の技術で作ったモンテカルロ法を使った AIにまったく太刀打ちできていない。
↓
Deep learningをうまく使って成果を出すには、それなりの知識と閃きが必要だ。
チートになってしまうが、そろそろ論文サルベージを始めるか・・・
いや、もう少し自力で頑張ってみよう。
解答を見てしまったら楽しさ半減・・・
付録:
(A) 人 vs COM : コンソール対戦プログラム
↓ 対戦出来ます。
あまり強いのはサーバー負荷が上がって BANされるかもしれないので、iteration=100, 200を公開いたします。
100 playouts : CvT 9665 オセロ歴10日レベル?
200 playouts : CvT 9832 オセロ歴30日レベル?

Webブラウザ対戦オセロも、ラッパーを介してこのプログラムの MCTSPlayerをそのまま動かしています。
実行例: playout 200回指定で実行する。
$ python main.py -i 200
こちら → ChatGPTにこのプログラムを解説してもらいました。
※なので… 私のコメントは邪魔になりそうなので消しました。
import othello_board
from othello_board import OthelloBoardEnv
from MCTSPlayer import MCTSPlayer
import argparse
BOARD_SIZE = 6
class HumanPlayer:
def select_move(self, env):
env.display()
legal = env.legal_moves()
while True:
move = input(f"合法手 {legal} から選んでください r c: ")
try:
r,c = map(int, move.split())
if (r,c) in legal:
return (r,c)
except:
pass
print("不正な入力。もう一度。")
def play_game( player1, player2, boardSize ):
env = OthelloBoardEnv( boardSize=boardSize )
while not env.game_over():
if env.current_player==1:
move = player1.select_move(env)
else:
move = player2.select_move(env)
env.step(move)
env.display()
black_count = sum(row.count(1) for row in env.board)
white_count = sum(row.count(-1) for row in env.board)
print(f"黒({othello_board.BLACK}): {black_count} 石, 白({othello_board.WHITE}): {white_count} 石")
w = env.winner()
print("結果:", "黒({othello_board.BLACK})勝ち" if w==1 else "白({othello_board.WHITE})勝ち" if w==-1 else "引き分け")
if __name__=="__main__":
parser = argparse.ArgumentParser(description="オセロAI対戦")
parser.add_argument("-i", type=int, default=1000, help="プレイアウト数")
parser.add_argument("-c", type=float, default=1.4, help="探索-活用バランスパラメータ")
args = parser.parse_args()
print(f"オセロ MCTS Lv.{args.i} と対戦")
p1 = MCTSPlayer(boardSize=BOARD_SIZE, iterations=args.i)
p2 = HumanPlayer()
play_game(p1, p2,boardSize=BOARD_SIZE)
import random
import math
class Node:
def __init__( self, state, parent=None, move=None ):
self.state = state
self.parent = parent
self.move = move
self.children = []
self.visits = 0
self.wins = 0
self.lg_moves = self.state.legal_moves()
def is_fully_expanded( self ):
return len(self.children) == len(self.lg_moves)
def best_child( self, c_param ):
choices = []
for child in self.children:
win_rate = child.wins / child.visits
explore_bonus = c_param * math.sqrt(math.log(self.visits) / child.visits)
uct_value = win_rate + explore_bonus
choices.append((uct_value, child))
max_choice = max(choices, key=lambda x: x[0])
best_choice = max_choice[1]
return best_choice
class MCTSPlayerSingle:
def __init__(self, iterations, boardSize, c_param, max_depth):
self.iterations = iterations
self.boardSize = boardSize
self.c_param = c_param
self.max_depth = max_depth
self.corners = [(0,0),(0,self.boardSize-1),(self.boardSize-1,0),(self.boardSize-1,self.boardSize-1)]
def heuristic_playout(self, state, moves):
for corner in self.corners:
if corner in moves:
return corner
return random.choice(moves)
def simulate(self, env):
root = Node(env.clone())
for _ in range(self.iterations):
node = root
while node.children and node.is_fully_expanded():
node = node.best_child(c_param=self.c_param)
legal_moves = node.state.legal_moves()
tried_moves = [child.move for child in node.children]
untried_moves = [m for m in legal_moves if m not in tried_moves]
if untried_moves:
move = random.choice(untried_moves)
new_state = node.state.clone()
new_state.step(move)
node = Node(new_state, parent=node, move=move)
node.parent.children.append(node)
sim_state = node.state.clone()
depth = 0
while not sim_state.game_over() and depth < self.max_depth:
moves = sim_state.legal_moves()
if moves:
move = self.heuristic_playout(sim_state, moves)
sim_state.step(move)
else:
sim_state.switch_player()
depth += 1
winner = sim_state.winner()
while node:
node.visits += 1
if node.state.current_player != winner:
node.wins += 1
node = node.parent
return [(child.move, child.visits, child.wins) for child in root.children]
class MCTSPlayer:
def __init__(self, boardSize, iterations=300, c_param=1.4, max_depth=30):
self.boardSize = boardSize
self.iterations = iterations
self.c_param = c_param
self.max_depth = max_depth
def select_move(self, env):
player = MCTSPlayerSingle(self.iterations, self.boardSize, self.c_param, self.max_depth)
children = player.simulate(env)
if len(children) > 0:
max_node = max(children, key=lambda node: node[1])
best_move = max_node[0]
return best_move
else:
return random.choice(env.legal_moves())
import copy
EMPTY, BLACK, WHITE = '.', '○', '●'
class OthelloBoardEnv:
def __init__(self, boardSize, state=None):
self.boardSize = boardSize
self.dirs = [(-1,-1),(-1,0),(-1,1),(0,-1),(0,1),(1,-1),(1,0),(1,1)]
if state is not None:
self.board = state
else:
self.board = [[0]*self.boardSize for _ in range(self.boardSize)]
mid = self.boardSize // 2
self.board[mid-1][mid-1], self.board[mid][mid] = (-1, -1)
self.board[mid-1][mid], self.board[mid][mid-1] = ( 1, 1)
self.current_player = 1
def clone(self):
env = OthelloBoardEnv(self.boardSize)
env.board = copy.deepcopy(self.board)
env.current_player = self.current_player
return env
def legal_moves(self):
moves = []
for r in range(self.boardSize):
for c in range(self.boardSize):
if self.board[r][c]==0 and self.can_flip(r,c):
moves.append((r,c))
return moves
def can_flip(self, r, c):
for dr, dc in self.dirs:
nr, nc = (r+dr, c+dc)
found = False
while (0 <= nr < self.boardSize) and (0 <= nc < self.boardSize) and (self.board[nr][nc] == -self.current_player):
nr += dr
nc += dc
found = True
if found and (0 <= nr < self.boardSize) and (0 <= nc < self.boardSize) and (self.board[nr][nc] == self.current_player):
return True
return False
def step(self, move):
r, c = move
self.board[r][c] = self.current_player
for dr, dc in self.dirs:
stones = []
nr, nc = (r+dr, c+dc)
while (0 <= nr < self.boardSize) and (0 <= nc < self.boardSize) and (self.board[nr][nc] == -self.current_player):
stones.append((nr,nc))
nr, nc = (nr+dr, nc+dc)
if stones and (0 <= nr < self.boardSize) and (0 <= nc < self.boardSize) and (self.board[nr][nc] == self.current_player):
for sr, sc in stones:
self.board[sr][sc] = self.current_player
self.current_player *= -1
if not self.legal_moves():
self.current_player *= -1
def game_over(self):
return not self.legal_moves() and not self.clone().switch_player().legal_moves()
def switch_player(self):
self.current_player *= -1
return self
def winner(self):
black = sum(row.count(1) for row in self.board)
white = sum(row.count(-1) for row in self.board)
return 1 if black > white else -1 if white > black else 0
def display(self):
print(' ' + ' '.join(str(c) for c in range(self.boardSize)))
for r in range(self.boardSize):
row = [EMPTY if cell==0 else (BLACK if cell==1 else WHITE) for cell in self.board[r]]
print(r, ' '.join(row))
player_str = f"Black({BLACK})" if self.current_player == 1 else f"White({WHITE})"
print(f"Current player: {player_str}")