759 views
この記事は最終更新から 389日 が経過しています。
【1】やりたいこと
前回の投稿では、CPU(1core), CPU(20cores), GPU の三者について、ベクトル計算速度を比較した。
(48) CPU(Single), CPU(Multi), GPUでベクトル計算速度を比較する。
結果は以下の通りだった。
ベクトル計算処理は GPUが圧倒的に速い。
だが、主メモリと GPUメモリ間のデータ転送コストが高い。
この GPUのデメリットは、以下の設計最適化で回避できる。
・GPU側で初期化・生成可能なデータは、GPU上で生成する。
・繰り返し使うデータはGPUメモリに保持し続ける。
・複数の段階を持つ処理をGPU内で完結させる。
・中間データもGPU内で管理する。
・転送量を削減する。(必要最小限のデータのみ送受信する)
・転送頻度を減らす。
・ピンメモリ(ページロックメモリ)を活用する。
・データ圧縮・エンコードによる転送量削減する。
等々…
これは後でやるとして、今回は、
前回投稿と同じプログラムを Python言語で実装し、
Python vs C言語で CUDAベクトル計算速度を比較してみる。
【2】やってみた
1) 計測内容
① メインメモリ上に 4バイト浮動小数点数データを 10億個 x A, Bの 2セット用意する。
② メインメモリ → GPUメモリ転送(GPUを使う場合)
③ C = A + B を計算する。
④ GPUメモリ → メインメモリ転送(GPUを使う場合)
以上
※GPUを使う場合、デバイス側(GPU側)に処理をポストした直後に関数から復帰するため、完了待ちのための同期処理を入れる。
でないと、実際よりも短時間で処理が完了したと勘違いしてしまうから。
nvccの場合
cudaDeviceSynchronize(); /* GPUと同期 */
CuPyの場合
cupy.cuda.Device(0).synchronize() # GPUと同期
PyTorchの場合
torch.cuda.synchronize() # GPUと同期
2) 比較するもの
下表の 5個のプログラムを作成。実行し、速度性能を比較してみたい。
| # | プログラムファイル名 | 説明 |
|---|---|---|
| 1 | cpu_1 | gccコンパイラによる生成コード (1コアで実行) |
| 2 | cpu_N | gccコンパイラ(OpenMP利用)による生成コード (20コアで並列実行) |
| 3 | gpu_nvcc | nvccコンパイラによる生成コード |
| 4 | gpu_cupy.py | Python(CuPy利用)スクリプト |
| 5 | gpu_torch.py | Python(PyTorch利用)スクリプト |
※Pythonプログラムから直接 CUDAライブラリ APIをコールすることも可能だが、手間がかかるので今回は調査対象としない。
3) 事前の予想
速度性能は、大差で「C言語実装 > Python言語実装」かな?
4) 実行結果
(1) 純粋なベクトル計算処理だけの実行時間を計測
以下に記した値は、10回以上実行した中で平均的な値を採用している。
正しくベクトル計算処理が実行できていることを確認するため、計算結果の積算値も表示した。
$ ./cpu_1 time: 1493.470 ms Sum of all elements: 3000000000.0 $ ./cpu_N time: 192.462 ms Sum of all elements: 3000000000.0 $ ./gpu_nvcc time: 15.551 ms Sum of all elements: 3000000000.0 $ python gpu_cupy.py time: 32.893 ms Sum of all elements: 3000000000.0 $ python gpu_pytorch.py time: 24.467 ms Sum of all elements: 3000000000.0
各 10回実行したが、毎回同じ順位だった。

CPU_1(single-core実行)があると他の結果が見辛いので、これを除外した図(↓ 拡大図)を記す。

ベクトル演算処理では GPU版(C言語実装版)が速い!
もう一度プログラムの説明を表示しておく。
| # | プログラムファイル名 | 説明 |
|---|---|---|
| 1 | cpu_1 | gccコンパイラによる生成コード (1コアで実行) |
| 2 | cpu_N | gccコンパイラ(OpenMP利用)による生成コード (20コアで並列実行) |
| 3 | gpu_nvcc | nvccコンパイラによる生成コード |
| 4 | gpu_cupy.py | Python(CuPy利用)スクリプト |
| 5 | gpu_torch.py | Python(PyTorch利用)スクリプト |
この結果だけを見ると、CPU実行版は問題外として、
.cu(C言語)の方が .py(Python言語)よりも若干速い。
→ 速度性能重視であれば C言語で書いた方が良い。
と言えるか。
PyTorch, PyCuのどちらも下位レイヤには CUDAを使っている。
→ 最終的に GPUを制御する時点では CUDAに到達する。
→ CUDAに到達するまでのオーバーヘッドが少ないほど速い。
→ 直接 CUDAを使っている自作 C言語プログラムの方が速い。
でも…
PyTorchや PyCuを使う理由は、高機能な便利ライブラリが手軽に使えるからだ。
手軽さ(保守性能) vs 速さ(速度性能)のトレードオフ を考慮し、プロジェクトにとって最適な選択をする。
(2) ラップタイム計測(処理時間の内訳を計測)する。
上記(1)は、純粋なベクトル計算処理だけの実行時間を計測 した結果だった。
でも、実際のシステムでは以下の一連の流れがあって、システムとして成立する。
・データ初期化
・データ転送(往路)
・ベクトル演算
・データ転送(復路)
プログラムにラップタイム計測機能を組み込み、各処理時間を見てみることにした。
計測結果は以下の通り。 数値の単位は[ms]
| 区間# | 計測区間 | cpu_1 | cpu_N | gpu_nvcc | gpu_cupy | gpu_torch |
|---|---|---|---|---|---|---|
| 1 | 主記憶上メモリ確保 | 0.071 | 0.027 | 0.026 | ※1 | ※1 |
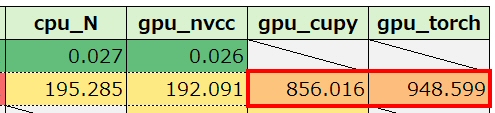
| 2 | 主記憶上データ初期化 | 2301.361 | 195.285 | 192.091 | 856.016 | 948.599 |
| 3 | GPU上メモリ確保 | - | - | 207.914 | 231.316 | ※2 |
| 4 | 主記憶 to GPUメモリデータ転送 | - | - | 480.013 | 468.536 | 576.750 |
| 5 | ベクトル演算実行 | 1494.705 | 189.228 | 15.922 | 32.939 | 24.536 |
| 6 | GPUメモリ to 主記憶データ転送 | - | - | 1294.304 | 591.921 | 1210.367 |
| 7 | ベクトル演算結果の積算値算出 | 1830.189 | 109.348 | 5.003 | 273.868 | 11.859 |
| 8 | GPU上メモリ解放 | - | - | 5.544 | 5.290 | 5.388 |
| 9 | 主記憶上メモリ解放 | 193.148 | 207.110 | 199.761 | 11.666 | 90.547 |
| Total | 5819.474 | 700.999 | 2400.578 | 2471.552 | 2868.045 |
※1 : この区間の処理時間は、区間#2に含まれている。
※2 : この区間の処理時間は、区間#4に含まれている。
どうも見づらいので Excelにコピペして整形する。

やっぱり 区間 #3, #4, #6 のオーバーヘッドの大きさ が目立つなぁ…
肝心要のベクトル演算実行では nvccによる GPU実行が圧倒的に高速 なだけに、他所の最適化が必須の作業だ。
その他・・・
・gpu_cupy, gpu_torchで区間#2の値が大きいのは?
→ クラスインスタンス生成によるオーバーヘッド発生か?(未調査)
→ 確保した領域を 0クリアしている?(未調査)
・区間#6について、GPU実行プログラムの中で gpu_cupyだけが相対的に速い。
→ なんでだ?(未調査)

【3】まとめ(?)
Pythonは遅いから速度性能重視ならば C言語で書け‼️
と思っていたが、そんなことはなかった。
2倍、3倍の速度性能差が許容できない場合だけ、C言語実装にこだわればよい。
✔️ 保守性能が求められる場面では、高生産性の Python言語実装を選択する。
✔️ 短期開発が求められる場面では、高生産性の Python言語実装を選択する。
✔️ どうしても速度チューニングしたい個所があれば、
C言語実装で GPU制御ライブラリを作り、Pythonプログラムから呼び出す。
当たり前だけど、やっぱりこのハイブリッド戦術が有効ですね。
【4】残件
・今回は Pythonプログラムから直接 CUDA Library APIを呼び出す実装を試していない。
→ 単純に CuPy, PyTorchのオーバーヘッド分だけ Python実装プログラムの方が遅かった可能性もある。
→ 要実験
・PyTorchには C/C++用ライブラリも提供されている。
→ これを使うと今回作った nvcc版よりもライブラリのオーバーヘッド分だけ遅くなる可能性もある
→ 要実験
【5】所感
・上記のプログラムでは、CPU側で生成した 10億個の 4バイト浮動小数点数データを GPUに転送しており、この送受信コストが高い。
→ 最初から GPU側でデータを生成 すれば、データ転送コストがほぼゼロになる。
→ どうしても CPU側から渡さなければならないデータを除き、GPUメモリの許す限り、最初から GPUメモリ上に作って置いておくのが良策だ。
・やっぱりこれに尽きる。
主メモリ(CPU側)とGPUメモリ間のデータ転送コストが高い。
↓
🗝 GPU側で初期化・生成可能なデータは、GPU上で生成する。
🗝 繰り返し使うデータはGPUメモリに保持し続ける。
🗝 複数の段階を持つ処理をGPU内で完結させる。
🗝 中間データもGPU内で管理する。
🗝 転送量を削減する。(必要最小限のデータのみ送受信する)
🗝 転送頻度を減らす。
🗝 ピンメモリ(ページロックメモリ)を活用する。
🗝 データ圧縮・エンコードによる転送量削減する。
・C++版 PyTorchを使って比較してみたらどうだろうか?
→ オーバーヘッドが増えて Python版との差が縮まるのでは?
付録:
最後に、今回使用したプログラムソースコードを置いておく。
後でまた使いたくなるかもしれない。
/*
compile:
(1) single-core実行
$ gcc cpu.c -o cpu_1 -L. -lmylib
(2) multi-core実行
$ gcc cpu.c -o cpu_N -L. -lmylib -fopenmp
*/
#include <stdio.h>
#include <stdlib.h>
#include <omp.h>
#include "mylib.h"
#define N 1000000000
////////////////////////////////////////////////////////////////////////////////
int main() {
LapInfo tmLap[30];
int iLap = 0;
set_lap(&tmLap[iLap], "Start"); iLap++; //@@@@@ Lap time記録
//--------------------------------------------------------------------------
/* データ作成 */
size_t size = N * sizeof(float);
float *A = malloc(size);
float *B = malloc(size);
float *C = malloc(size);
set_lap(&tmLap[iLap], "malloc"); iLap++; //@@@@@ Lap time記録
//--------------------------------------------------------------------------
// データ初期値セット
#pragma omp parallel for
for (int i = 0; i < N; i++) {
A[i] = 1.0f;
B[i] = 2.0f;
}
set_lap(&tmLap[iLap], "set value"); iLap++; //@@@@@ Lap time記録
//--------------------------------------------------------------------------
// 演算実行
#pragma omp parallel for
for (int i = 0; i < N; i++) {
C[i] = A[i] + B[i];
}
set_lap(&tmLap[iLap], "vector calculation"); iLap++; //@@@@@ Lap time記録
//--------------------------------------------------------------------------
// 積算値計算
double sum = 0.0;
#pragma omp parallel for reduction(+:sum) // reduction(+:sum):スレッドごとの部分和を最後に合計 → 安全
for (int i = 0; i < N; i++) {
sum += C[i];
}
set_lap(&tmLap[iLap], "calculate sum"); iLap++; //@@@@@ Lap time記録
//--------------------------------------------------------------------------
// メモリ解放
free(A); free(B); free(C);
set_lap(&tmLap[iLap], "free"); iLap++; //@@@@@ Lap time記録
//--------------------------------------------------------------------------
showLaps( tmLap, iLap );
printf("Sum of all elements: %.1f\n", sum);
return 0;
}
// compile:
// $ nvcc -Xcompiler -fopenmp gpu.cu -o gpu_nvcc -L. -lmylib
#include <stdio.h>
#include <cuda_runtime.h>
#include <thrust/device_ptr.h>
#include <thrust/reduce.h>
#include "mylib.h"
#define N 1000000000
#define THREADS_PER_BLOCK 1024
////////////////////////////////////////////////////////////////////////////////
__global__ void vector_add(float *A, float *B, float *C, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
C[i] = A[i] + B[i];
}
}
////////////////////////////////////////////////////////////////////////////////
int main() {
LapInfo tmLap[30];
int iLap = 0;
set_lap(&tmLap[iLap], "Start"); iLap++; //@@@@@ Lap time記録
//--------------------------------------------------------------------------
// データ作成
size_t size = N * sizeof(float);
float *A = (float*)malloc(size);
float *B = (float*)malloc(size);
float *C = (float*)malloc(size);
set_lap(&tmLap[iLap], "malloc"); iLap++; //@@@@@ Lap time記録
//--------------------------------------------------------------------------
#pragma omp parallel for
for (int i = 0; i < N; i++) {
A[i] = 1.0f;
B[i] = 2.0f;
}
set_lap(&tmLap[iLap], "set value"); iLap++; //@@@@@ Lap time記録
//--------------------------------------------------------------------------
// GPUメモリ獲得
float *d_A, *d_B, *d_C;
cudaMalloc(&d_A, size);
cudaMalloc(&d_B, size);
cudaMalloc(&d_C, size);
set_lap(&tmLap[iLap], "cudaMalloc"); iLap++; //@@@@@ Lap time記録
//--------------------------------------------------------------------------
// CPU → GPUデータ転送
cudaMemcpy(d_A, A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, B, size, cudaMemcpyHostToDevice);
set_lap(&tmLap[iLap], "cudaMemcpy H→D"); iLap++; //@@@@@ Lap time記録
//--------------------------------------------------------------------------
// 演算実行
int blocks = (N + THREADS_PER_BLOCK - 1) / THREADS_PER_BLOCK;
vector_add<<<blocks, THREADS_PER_BLOCK>>>(d_A, d_B, d_C, N);
cudaDeviceSynchronize(); // GPU側の処理終了待ち
set_lap(&tmLap[iLap], "vector calculation"); iLap++; //@@@@@ Lap time記録
//--------------------------------------------------------------------------
// GPU → CPUデータ転送
cudaMemcpy(C, d_C, size, cudaMemcpyDeviceToHost);
set_lap(&tmLap[iLap], "cudaMemcpy D→H"); iLap++; //@@@@@ Lap time記録
//--------------------------------------------------------------------------
// GPU上での積算値計算
thrust::device_ptr<float> dev_ptr(d_C);
float sum = thrust::reduce(dev_ptr, dev_ptr + N, 0.0f, thrust::plus<float>());
set_lap(&tmLap[iLap], "calculate sum on GPU"); iLap++; //@@@@@ Lap time記録
//--------------------------------------------------------------------------
// GPUメモリ解放
cudaFree(d_A); cudaFree(d_B); cudaFree(d_C);
set_lap(&tmLap[iLap], "cudaFree"); iLap++; //@@@@@ Lap time記録
//--------------------------------------------------------------------------
// メモリ解放
free(A); free(B); free(C);
set_lap(&tmLap[iLap], "free"); iLap++; //@@@@@ Lap time記録
//--------------------------------------------------------------------------
showLaps( tmLap, iLap );
printf("Sum of all elements: %.1f\n", sum);
return 0;
}
#ifndef _MYLIB_H
#define _MYLIB_H
#ifdef __cplusplus
extern "C" {
#endif
typedef struct {
struct timespec tm;
char memo[128];
}LapInfo;
// function prototypes
void set_lap( LapInfo* pLi, const char* pMemo );
double get_ms( struct timespec* pTm );
void showLaps( LapInfo* pLi, int nLap );
#ifdef __cplusplus
}
#endif
#endif // _MYLIB_H
/*
compile: build libmylib.so
$ gcc -Wall -fPIC -shared -o libmylib.so mylib.c
*/
#include <stdio.h>
#include <string.h>
#include <time.h> // timespecを使用
#include "mylib.h"
////////////////////////////////////////////////////////////////////////////////
void set_lap( LapInfo* pLi, const char* pMemo ){
clock_gettime( CLOCK_MONOTONIC, &pLi->tm);
strcpy( pLi->memo, pMemo );
}
////////////////////////////////////////////////////////////////////////////////
double get_ms( struct timespec* pTm ){
return pTm->tv_sec * 1000.0 + pTm->tv_nsec / 1e6;
}
////////////////////////////////////////////////////////////////////////////////
void showLaps( LapInfo* pLi, int nLap ){
double pre_ms = get_ms(&pLi[0].tm);
for(int i = 0 ; i < nLap ; i++){
double lap_ms = get_ms(&pLi[i].tm);
double dif_ms = lap_ms - pre_ms;
printf("[%d] %12.3f [ms] : %s\n", i, dif_ms, pLi[i].memo);
pre_ms = lap_ms;
}
double total_ms = pre_ms - get_ms(&pLi[0].tm);
printf("Total %12.3f [ms]\n", total_ms);
}
# $ pip install cupy-cuda12x # もし未インストールならば
import cupy as cp
import numpy as np
import time
import gc
N = 1000000000
laps = [] # ラップタイム用リスト
#///////////////////////////////////////////////////////////////////////////////
def record_lap(label):
t = time.perf_counter()
laps.append((label, t))
#///////////////////////////////////////////////////////////////////////////////
def show_lap():
for i in range(1, len(laps)):
label = laps[i][0]
lap_time = (laps[i][1] - laps[i-1][1]) * 1000
print(f"[{i}] {lap_time:10.3f} ms : {label}")
total_time = (laps[-1][1] - laps[0][1]) * 1000
print(f"\nTotal elapsed time: {total_time:.3f} ms")
#///////////////////////////////////////////////////////////////////////////////
def main():
record_lap("Start")
#---------------------------------------------------------------------------
# データ作成
A_host = np.full(N, 1.0, dtype=np.float32)
B_host = np.full(N, 2.0, dtype=np.float32)
record_lap("allocate and set value")
#---------------------------------------------------------------------------
# GPUメモリ獲得
A_gpu = cp.empty_like(A_host)
B_gpu = cp.empty_like(B_host)
record_lap("allocate GPU memory")
#---------------------------------------------------------------------------
# Host → Deviceデータ転送
cp.cuda.runtime.memcpyAsync( A_gpu.data.ptr, A_host.ctypes.data, A_host.nbytes, cp.cuda.runtime.memcpyHostToDevice, cp.cuda.Stream.null.ptr)
cp.cuda.runtime.memcpyAsync( B_gpu.data.ptr, B_host.ctypes.data, B_host.nbytes, cp.cuda.runtime.memcpyHostToDevice, cp.cuda.Stream.null.ptr)
cp.cuda.Device(0).synchronize() # 転送待ち
record_lap("memcpy Host to Device")
#---------------------------------------------------------------------------
# ベクトル演算実行
C_gpu = A_gpu + B_gpu
cp.cuda.Device(0).synchronize() # 計算終了待ち
record_lap("vector calculation")
#---------------------------------------------------------------------------
# GPU → CPUデータ転送
C_host = cp.asnumpy(C_gpu)
cp.cuda.Device(0).synchronize() # 転送終了待ち
record_lap("memcpy Device to Host")
#---------------------------------------------------------------------------
# 積算値計算
sum_all = np.sum(C_host)
record_lap("calculate sum")
#---------------------------------------------------------------------------
# GPUメモリ解放
del A_gpu, B_gpu, C_gpu
cp._default_memory_pool.free_all_blocks() # メモリプールのブロック解放
record_lap("free GPU memory")
#---------------------------------------------------------------------------
# メインメモリ解放
del A_host, B_host
gc.collect()
record_lap("free")
#---------------------------------------------------------------------------
# 結果表示
show_lap()
print(f"Sum of all elements: {sum_all:.1f}")
#//////////////////////////////////////////////////////////////////////////////
if __name__ == "__main__":
main()
import torch
import numpy as np
import time
import gc
N = 1000000000
laps = [] # ラップタイム用リスト
#///////////////////////////////////////////////////////////////////////////////
def record_lap(label):
t = time.perf_counter()
laps.append((label, t))
#///////////////////////////////////////////////////////////////////////////////
def show_lap():
for i in range(1, len(laps)):
label = laps[i][0]
lap_time = (laps[i][1] - laps[i-1][1]) * 1000
print(f"[{i}] {lap_time:10.3f} ms : {label}")
total_time = (laps[-1][1] - laps[0][1]) * 1000
print(f"\nTotal elapsed time: {total_time:.3f} ms")
#///////////////////////////////////////////////////////////////////////////////
def main():
record_lap("Start")
#---------------------------------------------------------------------------
# データ作成
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
A_host = np.full(N, 1.0, dtype=np.float32)
B_host = np.full(N, 2.0, dtype=np.float32)
record_lap("allocate and set value")
#---------------------------------------------------------------------------
# Host → Deviceデータ転送
A = torch.from_numpy(A_host).to(device)
B = torch.from_numpy(B_host).to(device)
record_lap("memcpy Host to Device")
#---------------------------------------------------------------------------
# ベクトル演算実行
C = A + B
torch.cuda.synchronize() # GPU側の処理終了待ち
record_lap("vector calculation")
#---------------------------------------------------------------------------
# GPU → CPUデータ転送
C_host = C.to("cpu").numpy()
torch.cuda.synchronize() # GPU側の処理終了待ち
record_lap("memcpy Device to Host")
#---------------------------------------------------------------------------
# 積算値計算
sum_tensor = torch.sum(C)
sum_all = sum_tensor.item() # GPU → CPUスカラ転送
record_lap("calculate sum")
#---------------------------------------------------------------------------
# GPUメモリ解放
del A, B, C
torch.cuda.empty_cache()
record_lap("free GPU memory")
#---------------------------------------------------------------------------
# メインメモリ解放
del A_host, B_host, C_host
gc.collect()
record_lap("free")
#---------------------------------------------------------------------------
# 結果表示
show_lap()
print(f"Sum of all elements: {sum_all:.1f}")
#//////////////////////////////////////////////////////////////////////////////
if __name__ == "__main__":
main()